이 포스팅은 아래 강의를 정리 및 일부항목을 추가한 것입니다. 매우 유익하고 설명이 자세하니 참고 바랍니다.
https://www.youtube.com/watch?v=58fuWVu5DVU
① 학습 수렴속도가 빠르다.
- 적은 epoch으로도 사용하지 않는 것 대비 높은 성능을 달성
② 가중치 초기화(weight initalization)에 대한 민감도를 감소시킨다.
- 모델을 학습할 때, 하이퍼파라미터의 변경은 모델의 수렴을 크게 좌우하지만, BN을 사용하면 덜 정교한 하이퍼파라미터 세팅이더라도 정상적으로 수렴한다. 예를 들어 learning-rate를 크게 잡아 모델이 학습이 안되는 경우에 BN을 적용시 정상적으로 수렴하는 것을 볼 수 있다.
③ 모델의 일반화(regularization) 효과가 있다.
- Test에서 BN을 사용시 정확도가 더 상승한다.
정리하면, BN은 학습 수렴속도를 빠르게 하며, 하이퍼파라미터 세팅에 대한 부담을 덜어주며 테스트에서도 좋은 성능을 보여준다.

-> 위와 같이 중간 레이어에 사용되며, dim=3이면 각각의 차원마다 감마와 배타의 파라미터를 적용해서 값을 조절한다. 작은 파라미터로 높은 성능향상을 이룰 수 있다.
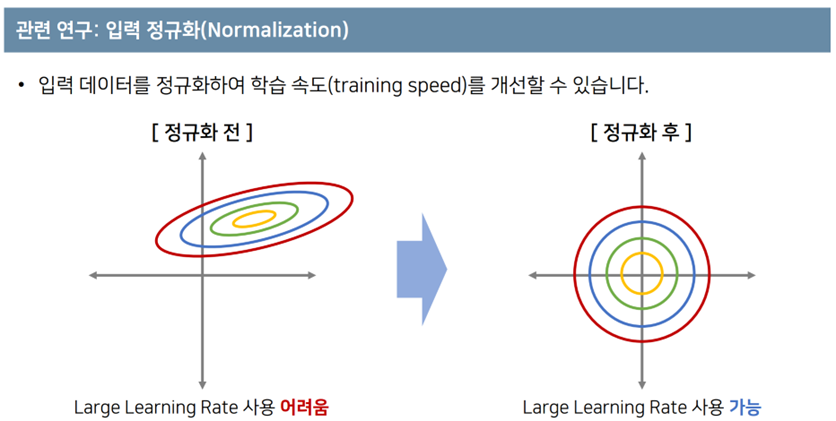
- 모델에 입력 값들을 정규화 함.
- 0~255의 값을 가지는 픽셀 값을 0~1 or -1~1로 정규화 해준다.
- 정규화시 학습 수렴속도가 빨라진다.
- 위의 그림은 입력이 2개의 픽셀로 구성된 흑백 이미지라고 가정을 했을때, 각 고리마다 데이터의 분포를 보여준다. 이미지가 너무 작아서 큰 의미는 없지만 가정을 해보자.
- [정규화 전]의 데이터에서는 가로축에는 variance가 크고, 세로축에는 variance가 작다. 이러한 데이터를 가지고 학습을 진행하면, 큰 learning rate를 사용하기 어려운데, 가중치 값이 많이 바뀐다면 세로축은 feature 값들의 많은 변화가 있을 수 있지만, 가로축은 변화가 거의 없을 수 있음. 따라서, [정규화 후]의 그림처럼 입력 데이터를 각각의 축에 대해서 학습에 수월한 데이터 분포를 가질 수 있도록 한다. 이 때, 상대적을 더 큰 learning rate를 사용 가능하므로 학습 수렴속도가 빨라진다는 장점이 있다.
- 정리하면, 입력 데이터의 정규화는 데이터의 각 차원에 대한 weight의 업데이트 비중을 동일하게 반영하여 학습 수렴속도를 올린다. 하지만, 이는 비슷한 값의 범위로의 scale 정규화이다.

- 일정 scale의 범위로 정규화(normalization) 하는 것과 다르게, 표준화(Standardization)은 입력 데이터를 평균=0, 분산=1인 정규분포를 따르도록 한다.
- 각 축(dim)에 대해서 위와 같은 공식을 적용한다.
- 그렇다면, 보통 vision에서는 표준화를 주로 사용하는데(실은 0~255->0~1로 텐서화 하고, 여러 data aug 수행 후 표준화를 수행함), 그 이유가 무엇일 까? 찾아본 바로는 이상치에 대한 영향력을 줄여주고 데이터의 상관관계를 더 잘 파악할 수 있다고 하는데 잘 납득이 가지 않는다. 다른 한편으로는 입력 데이터의 정규화는 첫 번째 레이어에 주로 영향을 미친다고하고, 평균0,분산1로 정규화 되어 있지 않으면 weight에 학습에 민감하게 영향을 미치게 된다고 한다. 따라서 안정된 학습을 위해서 weight,bias가 0에 가깝게 학습되도록 입력 데이터의 분포도 표준화하는 것이다. https://youtu.be/wEoyxE0GP2M?t=1635
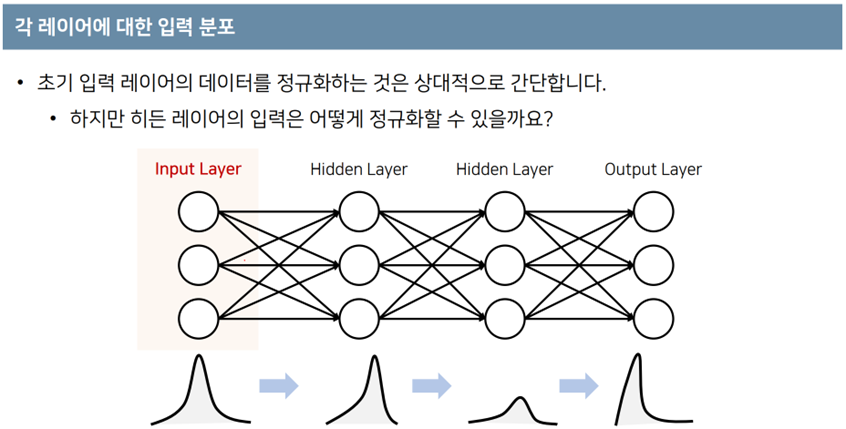
- 입력 데이터의 정규화로 인한 성능 향상은 증명됨.
- 히든 레이어의 정규화로 성능을 올리고자 하는 것이 BN이다.

- 입력에 대해서 mini-batch에서의 각 차원에 평균과 분산을 구하고 이를 정규화(표준화와 비슷하다)
- 학습 가능한 파라미터 감마(scale), 베타(shift)를 적용
- 감마와 베타는 각 차원마다 존재한다.
- 이를 MLP에 대해서 도식화하면 다음과 같다.

- 입력 feature dim=3으로 가정했을 때의 과정이다. 학습가능한 파라미터 감마, 배타도 차원 수만큼 존재함.
- 이를 CNN에 대해서 도식화 하면 다음과 같다.
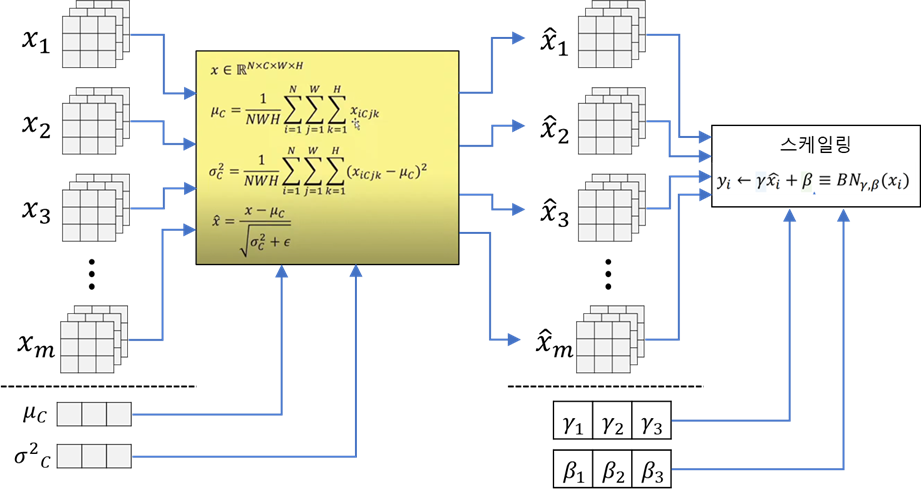
- where, N : mini-batch, C : channel, W : Width, H : Height
- batch단위로 각 채널에 대해서 모든 픽셀값들의 평균과 분산을 구하고 정규화(표준화, mean=0, var=1)해준다.
- 학습 가능한 파라미터 감마와 배타로 각 채널마다 스케일링한다.
- 일반적인 BN의 사용법은 다음과 같다.
weight -> BN -> activation_function
- 여러가지 feature normalization
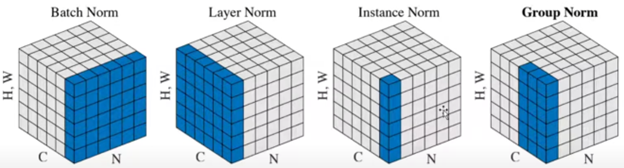
- 파란색 부분이 정규화 되는 target,
https://www.youtube.com/watch?v=1JmZ5idFcVI

- BN은 활성화 함수 직전에 수행되기 때문에 위와 같은 문제가 발생할 수 있음.
- 감마와 배타는 비선형성을 적절히 유지할 수 있도록 동작할 수 있다.
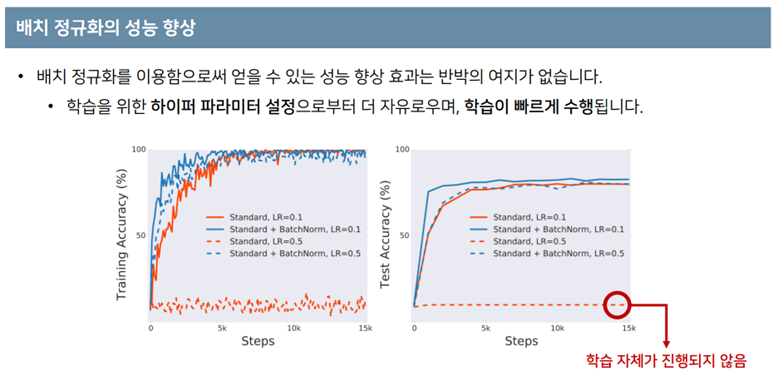
- BN을 적용했을 시에, LR의 크기에 덜 민감하게 수렴하는 모습을 볼 수 있음.
- 특히, 왼쪽 그림의 주황색 점 그래프에서 BN을 사용하지 않고 큰 lr을 수행할 경우 학습이 안되는 모습
- 또한, test에서의 성능도 훨씬 좋다.

- 추론에서는 mini-batch로 얼마나 들어올지도 모르기 때문에, 조금 다르게 BN을 수행한다.
- Train에서 몇 개의 mini-batch들의 이동평균과 분산을 구해주고, 이를 test에서 평균과 분산으로 사용
- test에서 이동 평균 및 분산과 학습된 파라미타 감마,배타를 사용해 BN을 수행한다.

- 왼쪽의 그래프는 입력에 대한 단일 차원(x)에서의 분포를 예시로 보여준다.
- 테스트에서 학습에서의 분포와 다른 분포가 들어올 경우 예기치 못한 성능하락이 발생할 수 있음.
-> 이러한 현상을 공변량 변화(Covariate Shift)라고 한다.
- 예를 들어, 줄무늬가 없는 고양이에 대해서만 학습하다가 테스트에서 줄무늬가 있는 고양이를 추론한다고 할 때 공변량 변화가 발생할 수 있다.

- 모델의 입력에서만 공변량 변화가 발생하는 것이 아닌, 모델의 내부에서의 각 feature들에 대해서도 공변량 변화가 발생할 수 있다는 가정. 이게, 내부적인 공변량 변화(Internal Covariate Shift)라고 한다.
- 위의 그림에서 입력은 정규화(or표준화)를 통해 비슷한 입력분포가 들어오지만 다음 히든 레이어부터는 정규화를 해주지 않아 학습 스탭마다 다른 분포가 들어올 수 있고, 이것이 모델의 수렴속도를 제한한다는 주장이였다.
- 하지만, BN의 성능 향상은 ICS의 감소로 인한 것일까? 라는 의문이 제기되고,
- 후속 연구에 의해 BN의 효과와 ICS의 감소는 큰 상관이 없다는 주장이 제기되었다. 꼭, ICS가 감소하지 않더라도 성능향상이 가능하다는 것을 증명한다.

- 왼쪽의 그래프에서와 같이 기존 모델보다 BN+noisy한 모델이 성능이 더 좋은 것을 확인
- ICS가 증가하더라도, 각각의 히든 레이어의 분포가 불안전하게 들어가더라도 여전히 BN의 효과를 볼 수 있음.
- 또한 오른쪽 분포의 그림에서, BN을 사용한 것과 기존(standarad)의 ICS의 차이가 거의 없고, 오히려 BN이 더 불안전한 것을 보이기도 한다. 해당 히스토그램에서 depth는 특정 레이어에서의 매 학습스텝마다의 분포를 보여준다.
- 그렇다면, 어떤 이유로 BN의 효과가 나타난 것일까?

- BN말고도 L1-norm, L2-norm과 같이 smoothing하게 하는 기법을 사용해도 비슷한 효과를 얻을 수 있음.
- smoothing하다는 말은 loss값의 변동이 작고 gradient의 크기또한 작다는 말. 그러므로 매스탭마다 조금씩 가중치를 업데이트 하므로 부드로운 landscape를 형성할 수 있다.
'Deep Learning (AI) > 이론 및 기술면접 정리' 카테고리의 다른 글
| [DL] 오토인코더(Autoncoder) (39) | 2023.08.23 |
|---|---|
| Cost Function은 무엇이며, 알고 있는 cost function에 대해서 말해주세요 (4) | 2023.08.04 |
| MLP에서 1x1을 사용해서 Bottleneck 구조를 설계하고, 그렇게 설계한 이유는? (1) | 2023.08.03 |
| 1x1 convolution은 언제 사용되며 의미와 효과? (0) | 2023.08.03 |
| 딥러닝은 무엇이며, 머신러닝과의 차이점은? (0) | 2023.08.03 |
